Verarbeitet man große Datenmengen, leidet nicht selten die Performance von Datenverarbeitungsprozessen. Die Initiative mit dem Titel “Leveraging the Power of Enterprise Databases” wurde vor einigen Jahren hierzu gestartet. In diesem Blogbeitrag zeigen wir Ihnen zwei neue Implementierungen, die Ihre Bearbeitungszeiten enorm reduzieren können.
Viele Prozesse in ArcGIS Desktop lesen die Daten zeilenweise aus der Datenbank, bearbeiten die Werte (Geometrie, Attribute) und schreiben sie wieder in die Tabelle zurück. Das hat den Vorteil, dass man bei der Bearbeitung nicht auf den Funktionsumfang von SQL eingeschränkt ist, sondern im Prinzip unbegrenzte Möglichkeiten hat (ArcObjects, Python, Arcade …). Diese Freiheit der Verarbeitung außerhalb der Datenbank hat aber ihren Preis: in Form von Bearbeitungsgeschwindigkeit. Aber es gibt neue Alternativen.
Vergleicht man die Performance von Datenverarbeitungsprozessen, dann stellt man immer wieder fest, dass die Verarbeitung in der Datenbank mit SQL um ein Vielfaches performanter ist als die zeilenweise Verarbeitung in ArcObjects. In der Vergangenheit wurde viel Energie darauf verwendet, in ArcGIS die Lese- und Schreiboperationen auf die Datenbank so schnell wie möglich zu machen, um den Performanceverlust möglichst auszugleichen. Bei der Verarbeitung kleinerer Datenmengen ist das auch gut gelungen. Für der Bearbeitung großer Datenmengen (> 100.000 Zeilen) wurde vor einigen Jahren die Initiative unter dem Titel “Leveraging the Power of Enterprise Databases” gestartet. Das Ziel war, für bestimmte Prozesse, die große Datenmengen verarbeiten sollen und die auf der Grundlage von SQL umgesetzt werden können, Alternativen zu entwickeln und anzubieten. In der Version ArcGIS Pro 2.7 finden sich dazu zwei neue Implementierungen, die hier im Vergleich zur Standardimplementierung vorgestellt werden: “Select Layer By Location” und “Calculate Field”
Select Layer by Location
Dieses Werkzeug wählt Features auf Grundlage einer räumlichen Beziehung zu Features in einem anderen Dataset aus. Wenn der festgelegte Parameter der Beziehung (Relationship) erfüllt ist, wird das Eingabe-Feature ausgewählt.
Im Folgenden wird der Unterschied zwischen Beziehungs-Parameter INTERSECT und INTERSECT_DBMS vorgestellt:
INTERSECT — Die Features im Eingabe-Layer werden ausgewählt, wenn Sie ein Auswahl-Feature schneiden. Dies ist die Standardeinstellung.
INTERSECT_DBMS — Die Features im Eingabe-Layer werden ausgewählt, wenn Sie ein Auswahl-Feature schneiden. Diese Option gilt nur für eine Enterprise-Geodatabases. Wenn alle Anforderungen erfüllt sind (siehe unten), wird die Auswahl im Enterprise-Geodatabase-DBMS und nicht auf dem Client verarbeitet. Diese Option bietet möglicherweise eine bessere Performance als die Durchführung der Auswahl auf dem Client.
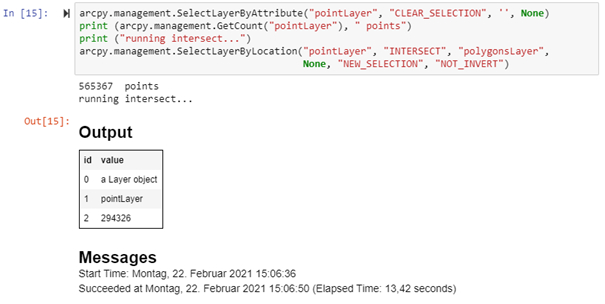
In einem Notebook werden aus einem Punkt-Layer (565367 Punkte) diejenigen Punkte ausgewählt, die sich innerhalb der Flächen eines Polygon-Layers befinden. Im ersten Beispiel wird dabei der Beziehungs-Parameter INTERSECT benutzt. Der Vorgang dauert in diesem Beispiel 13,42 Sekunden.
Für die Anwendung der Beziehungs-Parameters INTERSECT_DBMS müssen folgende Voraussetzungen erfüllt sein:
- Beide Layer sind im gleichen Enterprise-Geodatabase-Workspace.
- Die Datenbank ist eine IBM DB2, Oracle, PostgreSQL, SAP HANA oder Microsoft SQL Server.
- Beide Layer verwenden den gleichen Geometrie-Speichertyp: ST_GEOMTERY bei IBM DB2, Oracle, PostgreSQL und SAP HANA, MSSQL Geometry/MSSQL Geography bei Microsoft SQL Server, PostGIS bei PostgreSQL und SDO_GEOMTERY bei Oracle.
- Der Parameter “SUCHENTFERNUNG” ist nicht festgelegt.
- Der Parameter “AUSWAHLTYP” ist “NEW_SELECTION”.
- Wenn nur aus einer Teilmenge der Input-Features ausgewählt werden soll, muss diese als Layer-Definitionsabfrage definiert sein.
Außerdem zu beachten:
Die Auswahl erfolgt ohne Berücksichtigung einer XY-Toleranz (eine Fuzzy-Toleranz wird in der DBMS/SQL nicht unterstützt). Das kann unter Umständen zu unterschiedlichen Resultaten führen.
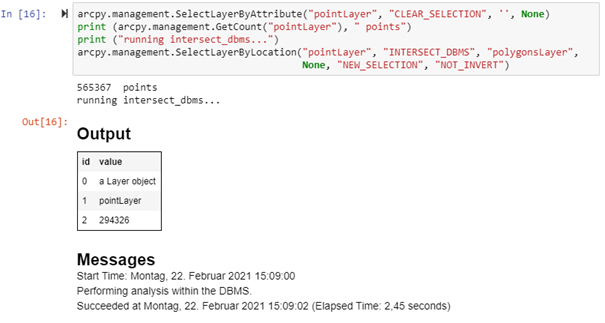
In diesem Fall dauert der gleiche Vorgang nur 2,45 Sekunden – im Vergleich dazu 13,42 Sekunden in der Standardeinstellung.
Calculate Field
Mit diesem Werkzeug werden die Werte eines Feldes für eine Feature-Class, einen Feature-Layer oder ein Raster berechnet.
Wir zeigen hier den Unterschied zwischen PYTHON3/ARCADE und SQL.
SQL war in den vorangegangenen Versionen von ArcGIS Pro schon für Feature-Services verfügbar. Jetzt kann der Parameter auch für Tabellen in einer Enterprise Geodatabase verwendet werden.
SQL-Ausdrücke wurden implementiert, um eine schnellere Berechnung zu unterstützen. Statt Features oder Zeilen einzeln nacheinander zu berechnen, wird eine einzelne Anforderung an den Feature-Service bzw. an die Datenbanktabelle gesendet.
Das folgende Beispiel zeigt die Feldberechnung für 565367 Datensätze zunächst einmal mit PYTHON3 und mit ARCADE:
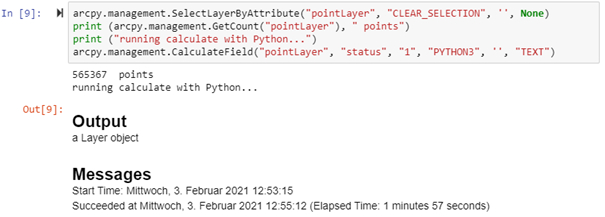
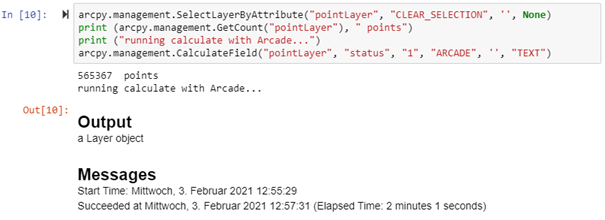
Beide Vorgänge dauern ca. 2 Minuten. Im nächsten Abschnitt wurde der SQL-Parameter verwendet:
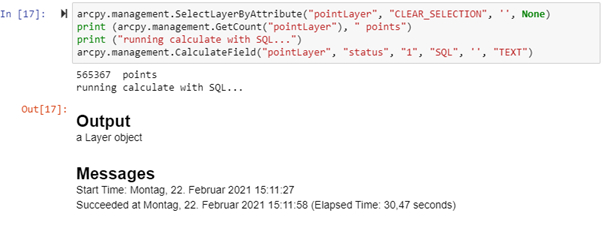
Datenverarbeitungsprozesse in ArcGIS Pro können auf diese Weise um ein Vielfaches beschleunigt werden – in diesem Beispiel 30 Sekunden anstatt 2 Minuten.